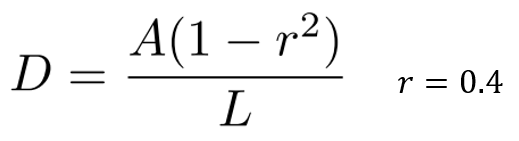代码下载及环境配置 首先是代码下载,DBNet代码
使用 git clone 的方式下载上述代码即可。
使用conda来install一些必要的库
我对代码文件夹中的README.MD文件做了一个简化,只需要按照接下来的步骤按照虚拟环境即可,若中途出现超时报错,请多换几次源(对此深感无奈)。
先执行一下命令,构建一个初步的虚拟环境
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 conda create -n dbnet python=3.6 activate dbnet conda install ipython pip pip anyconfig==0.9.10 pip future==0.18.2 pip imgaug==0.4.0 pip matplotlib==3.1.2 pip numpy==1.17.4 pip opencv-python==4.1.2.30 pip Polygon3==3.0.8 pip pyclipper==1.1.0.post3 pip PyYAML==5.2 pip scikit-image==0.16.2 pip tensorboard==2.1.0 pip tqdm==4.40.1 pip install natsort pip install addict pip install cudatoolkit==10.2.89
接下来的几个库,需要我们下载.whl来辅助下载,否则会非常慢,甚至找不到下载资源。
他们分别是这几个库
cudnn-7.6.5-cuda10.2_0 Shapely-1.6.4.post2-cp36-cp36m-win_amd64 torch-1.7.1-cp36-cp36m-win_amd64 torchvision-0.8.2-cp36-cp36m-win_amd64
我在这里放一下百度网盘的连接
链接:https://pan.baidu.com/s/1r1mpHcDWKvNwUqR60h5-Vw
训练步骤 首先需要修改一些配置文件
进入git clone好的代码文件中。
首先看config文件夹下的一些配置文件:这些配置文件中的内容包括了backbone使用何种网络模型来进行特征提取,
是否采用dcn空洞卷积来增大感受野,训练数据和测试数据的一个存放位置,是否启用预训练模式,epochs,各种参数等…
接着查看tools文件夹下的train.py
将原来的”config/…….”配置文件的相对路径 改为具体采用的配置方案的配置文件的绝对路径
例如我采用的是icdar2015_resnet18_FPN_DBhead_polyLR.yaml
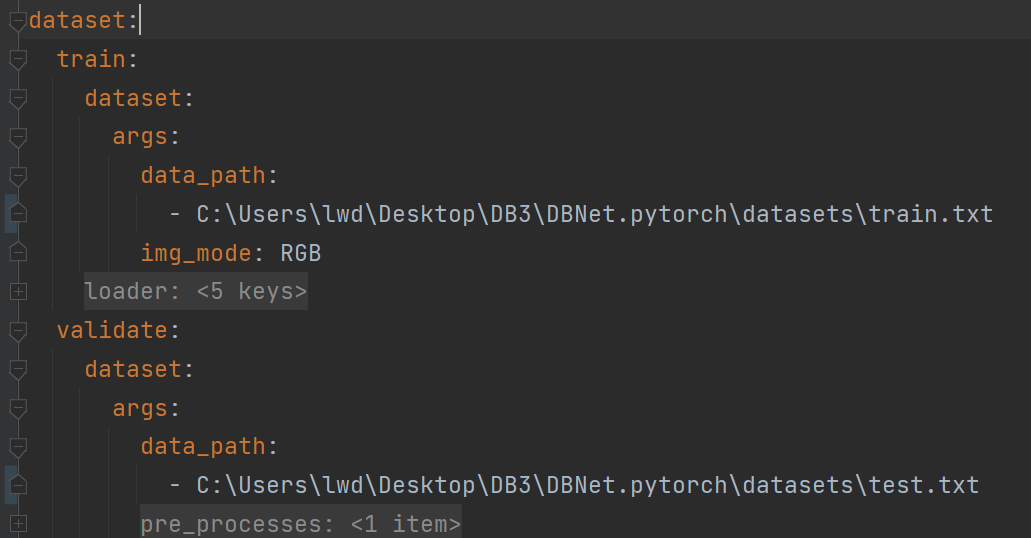
改好之后,按照图片中的格式,修改所选择的配置文件中一些关于数据的存放路径(注:train.txt和test.txt文件夹还未生成,先按代码文件夹下的README.MD,在datasets文件夹下,分别放好train,test文件夹下的gt和img )
数据集下载链接
接下来按照load.py代码,生成train.txt和test.txt两个文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 import osdef get_images (img_path ):''' find image files in data path :return: list of files found ''' 'jpg' , 'png' , 'jpeg' , 'JPG' , 'PNG' ]for parent, dirnames, filenames in os.walk(img_path):for filename in filenames:for ext in exts:if filename.endswith(ext):break print ('Find {} images' .format (len (files)))return sorted (files)def get_txts (txt_path ):''' find gt files in data path :return: list of files found ''' 'txt' ]for parent, dirnames, filenames in os.walk(txt_path):for filename in filenames:for ext in exts:if filename.endswith(ext):break print ('Find {} txts' .format (len (files)))return sorted (files)if __name__ == '__main__' :import json'./test/img' './test/gt' len (files)assert len (files) == len (txts)with open ('test.txt' , 'w' ) as f:for i in range (n):'\t' + txts[i] + '\n' print ('dataset generated ^_^ ' )
运行tools文件夹下的train.py,即可开始训练
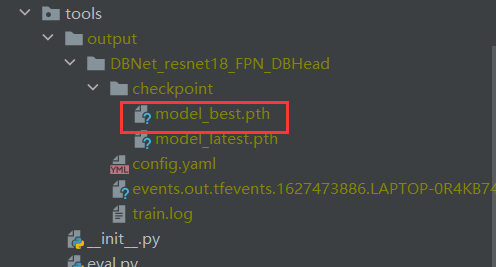
训练结果model_best.pth位置如下
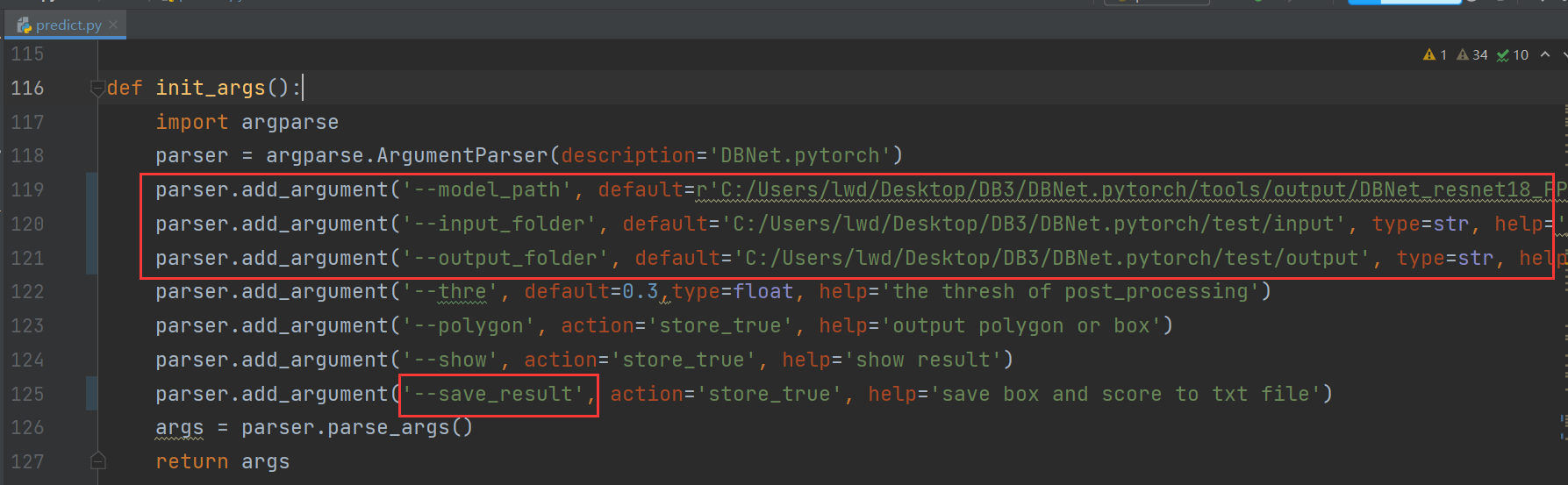
预测步骤 将红框中的路径,全部改为对应的model_best.pth ,准备预测的图片,和预测结果的存放文件的绝对地址。
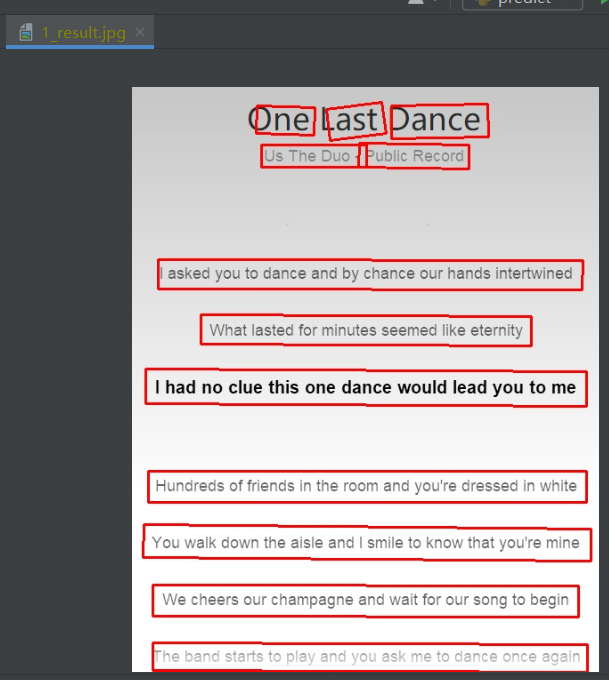
注意第二个红框,原代码中拼写有误。进行修改之后即可运行predict.py,然后即可在输出文件中查看训练结果。
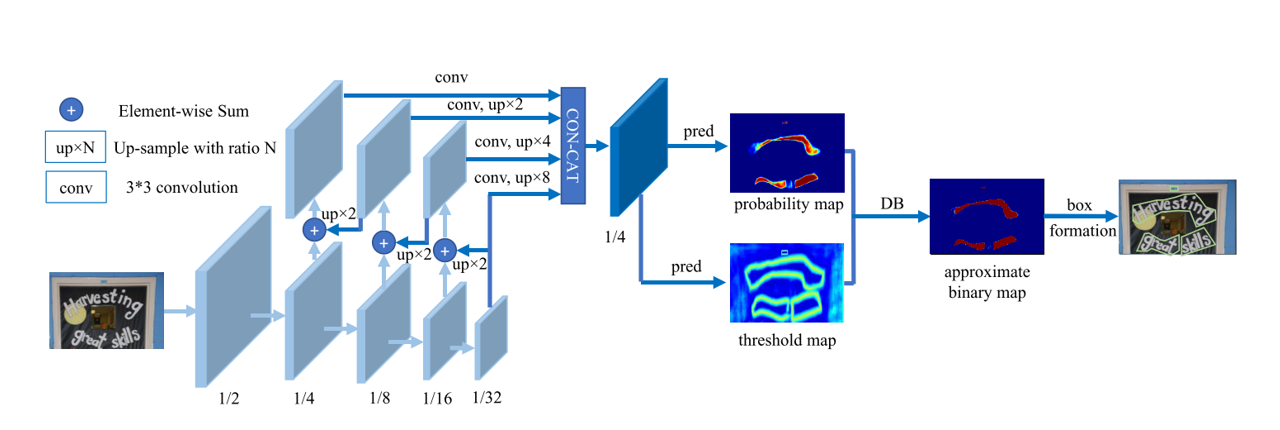
整体网络模型构建代码 models/model.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 class Model (nn.Module ):def __init__ (self, model_config: dict ):""" PANnet :param model_config: 模型配置 """ super ().__init__()Dict (model_config)'type' )'type' )'type' ) f'{backbone_type} _{neck_type} _{head_type} ' def forward (self, x ):'bilinear' , align_corners=True )return y
models/backbone/resnet.py Resnet18的网络模型构建
特征提取
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 class BasicBlock (nn.Module ):1 def __init__ (self, inplanes, planes, stride=1 , downsample=None , dcn=None ):super (BasicBlock, self).__init__()is not None True ) False if not self.with_dcn: 3 , padding=1 , bias=False )else : from torchvision.ops import DeformConv2d'deformable_groups' , 1 )18 3 , padding=1 )3 , padding=1 , bias=False )def forward (self, x ):if not self.with_dcn: else :if self.downsample is not None :return outdef forward (self, x ):return x2, x3, x4, x5
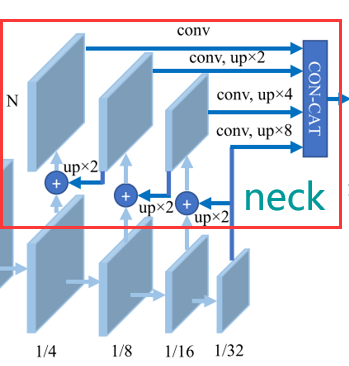
models/neck/FPN.py FPN特征金字塔
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 def forward (self, x ):return xdef _upsample_add (self, x, y ):return F.interpolate(x, size=y.size()[2 :]) + ydef _upsample_cat (self, p2, p3, p4, p5 ):2 :]return torch.cat([p2, p3, p4, p5], dim=1 )
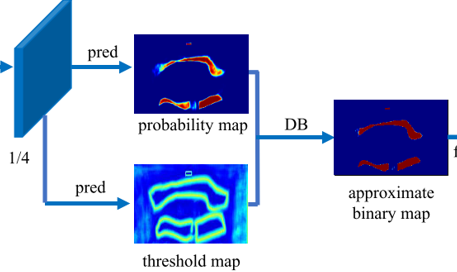
models/head/DBHead.py DBNet核心模型
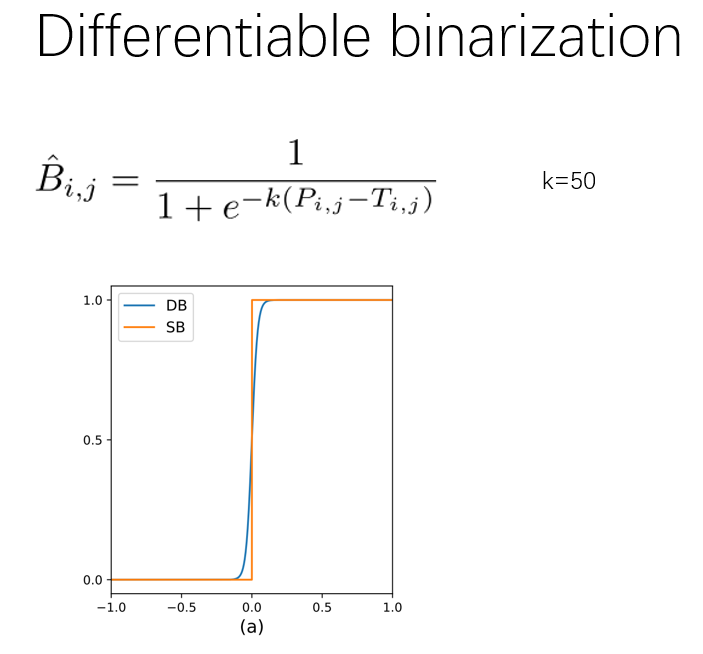
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 class DBHead (nn.Module ):def __init__ (self, in_channels, out_channels, k = 50 ):super ().__init__()4 , 3 , padding=1 ),4 ),True ),4 , in_channels // 4 , 2 , 2 ),4 ),True ),4 , 1 , 2 , 2 ),def forward (self, x ):if self.training:1 )else : 1 )return y
def step_function (self, x, y ):return torch.reciprocal(1 + torch.exp(-self.k * (x - y)))
流程: 主model.py最终从backbone–neck–DB得到的y,如果是训练,则传给train.py;如果是预测,则传给predict.py。
训练部分代码 一些训练的设置,重点是其在评估方法时,采用的是quad_metric.py中的方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 'post_processing' ])'metric' ])
trainer/trainer.py 重点: 其中评估方法quad_metric.py文件1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 'img' ])def _eval (self, epoch ):
训练的batch以及总体的评估 utils/ocr_metric/icdar2015/quad_metric.py1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 class QuadMetric ():def __init__ (self, is_output_polygon=False ):def measure (self, batch, output, box_thresh=0.6 ):'text_polys' ]'ignore_tags' ]for polygons, pred_polygons, pred_scores, ignore_tags in zip (gt_polyons_batch, pred_polygons_batch, pred_scores_batch, ignore_tags_batch):dict (points=np.int64(polygons[i]), ignore=ignore_tags[i]) for i in range (len (polygons))]if self.is_output_polygon: dict (points=pred_polygons[i]) for i in range (len (pred_polygons))]else : return resultsdef validate_measure (self, batch, output, box_thresh=0.6 ):return self.measure(batch, output, box_thresh)def evaluate_measure (self, batch, output ):return self.measure(batch, output), np.linspace(0 , batch['image' ].shape[0 ]).tolist()def gather_measure (self, raw_metrics ):for batch_metrics in raw_metricsfor image_metrics in batch_metrics]return {'precision' : precision,'recall' : recall,'fmeasure' : fmeasure
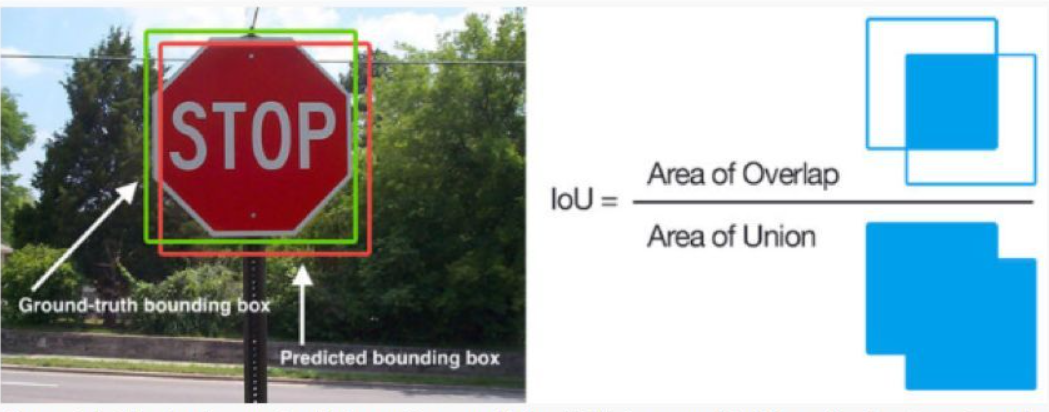
utils/ocr_metric/icdar2015/detection/iou.py def evaluate_image (self, gt, pred ):
def get_union (pD, pG ):return Polygon(pD).union(Polygon(pG)).areadef get_intersection_over_union (pD, pG ):return get_intersection(pD, pG) / get_union(pD, pG)def get_intersection (pD, pG ):return Polygon(pD).intersection(Polygon(pG)).area
Precision精确率, Recall召回率,是二分类问题常用的评价指标。
预测部分代码 'post_processing' ])
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 if str (self.device).__contains__('cuda' ):0 ], score_list[0 ]
重点:进行后处理操作 训练或者预测中====
用来获取训练train.py时的train数据集中的文本框,
预测predict.py待预测图片的文本框的操作
post_processing/seg_detector_representer.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 def __init__ (self, thresh=0.3 , box_thresh=0.7 , max_candidates=1000 , unclip_ratio=1.5 ):def __call__ (self, batch, pred, is_output_polygon=False ):return boxes, scores
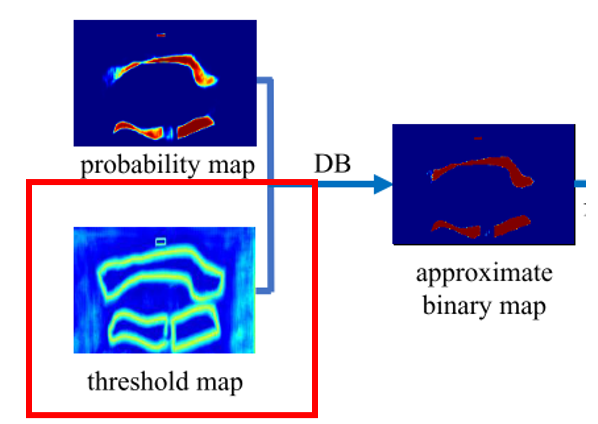
label标签制作 根据人工标记的gt框(一系列坐标点),进行一些膨胀(dilate)和缩小(shrink)的操作
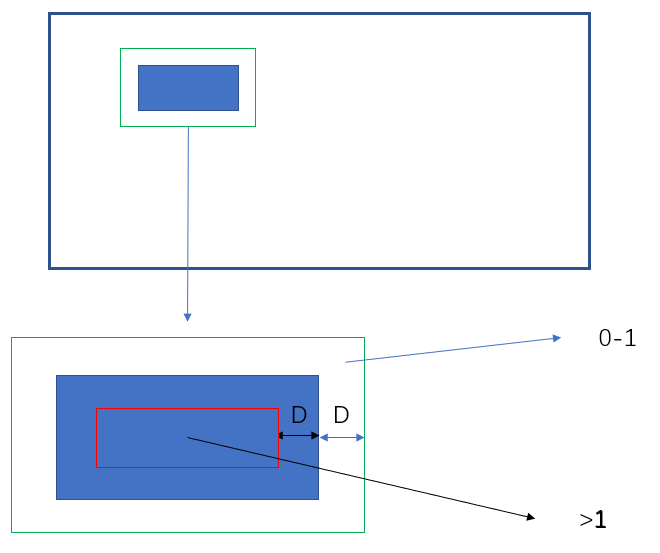
膨胀和缩小的距离:
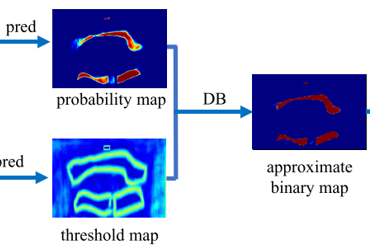
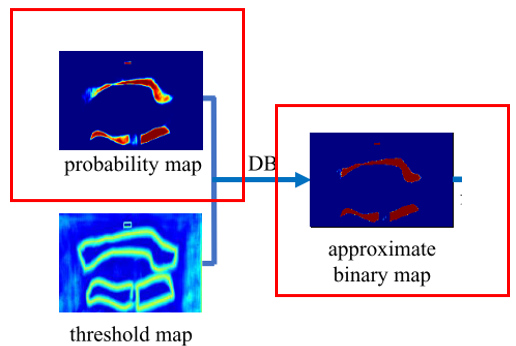
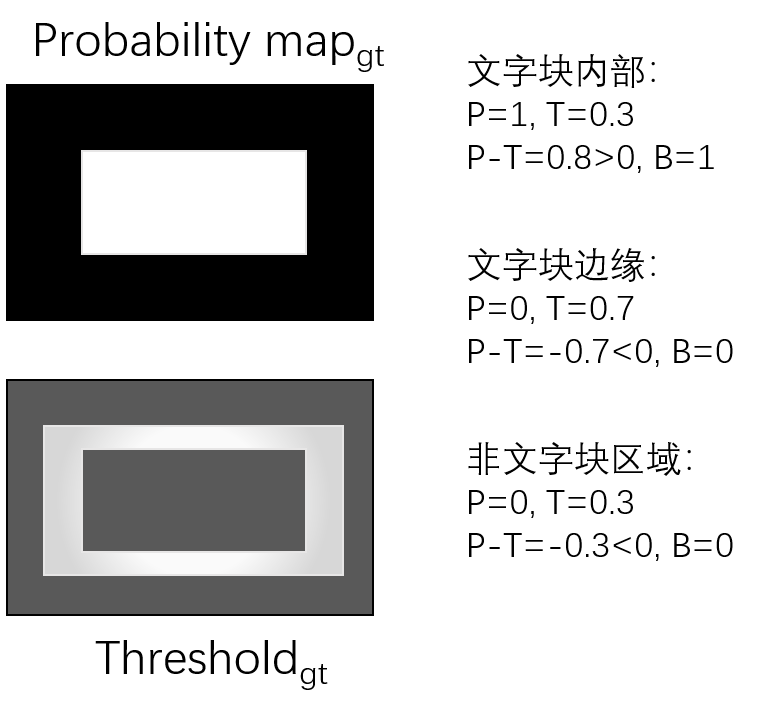
并且做一些gt框内的计算来得到probability_map和threshold_map
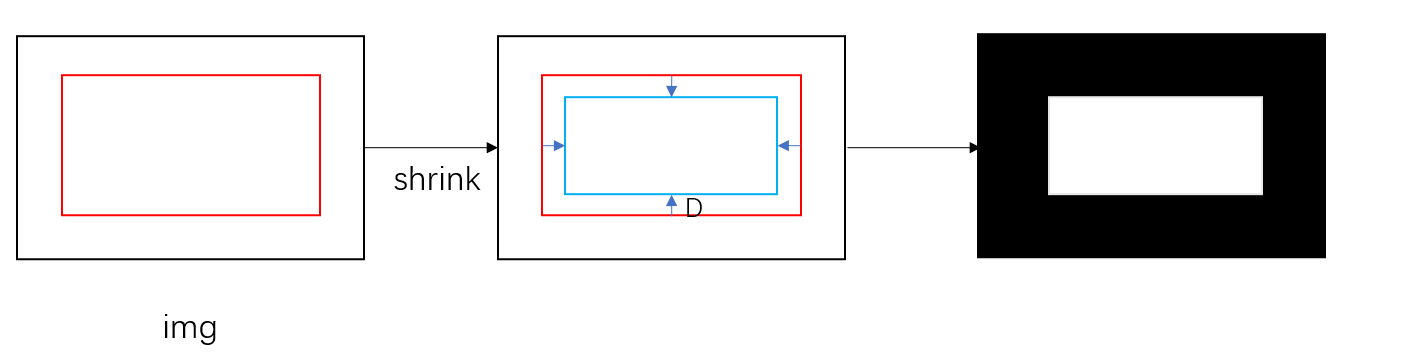
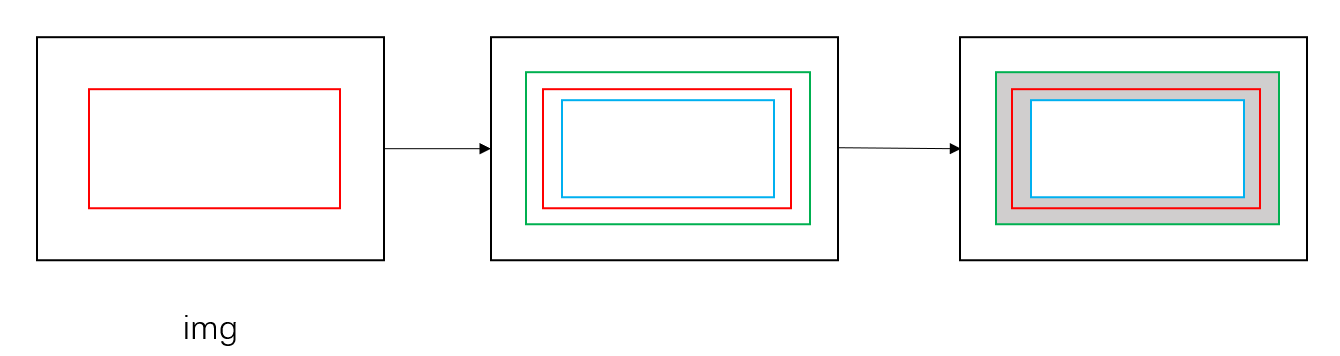
data_loader/modules/make_shrink_map.py 一个shrink操作: 红框为gt框,蓝框为shrink后的结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 def shrink_polygon_pyclipper (polygon, shrink_ratio ):from shapely.geometry import Polygonimport pyclipper 1 - np.power(shrink_ratio, 2 )) / polygon_shape.lengthtuple (l) for l in polygon]if shrinked == []:else :0 ]).reshape(-1 , 2 )return shrinked
data_loader/modules/make_border_map.py shrink操作 + dilate操作: 红框为gt框,蓝框为shrink框,绿框为dilate框
1 - np.power(self.shrink_ratio, 2 )) / polygon_shape.lengthtuple (l) for l in polygon]0 ])
处理后的Distance map
0 , 1 )1 , xmin_valid:xmax_valid + 1 ] = np.fmax(1 - distance_map[1 , xmin_valid:xmax_valid + 1 ])
两个map的计算 shrink_map 和 dilate_map的一个计算