版本:
python 3.7 .9 2.2 1.1 .1 1.1 .1 2.10 .0 2.3 .1 8.1 .0 1.20 .1 2.0 .0 8.0 .23 1.3 .14
软件: anaconda3 + Pycharm ,由anaconda3创建虚拟环境,并在Pycharm上对接
conda源:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 set show_channel_urls yesset show_channel_urls yes
本次实验由于数据集较少,所以采用了图像增强的方法,对数据进行了增强
train_datagen = ImageDataGenerator(rescale=1/255, rotation_range=40, height_shift_range=0.2, width_shift_range=0.2, shear_range=0.2, zoom_range=0.2, horizontal_flip=True, vertical_flip=True, validation_split=0.1
共尝试三个模型:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 model = Sequential([32 , kernel_size=3 , padding='same' , activation='relu' , input_shape=(300 , 300 , 3 )),2 ),64 , kernel_size=3 , padding='same' , activation='relu' ),2 ),32 , kernel_size=3 , padding='same' , activation='relu' ),2 ),32 , kernel_size=3 , padding='same' , activation='relu' ),2 ),64 , activation='relu' ),6 , activation='softmax' )compile (loss='categorical_crossentropy' ,'adam' ,'acc' ])
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 model = Sequential()32 , (3 , 3 ), input_shape=(300 , 300 , 3 ), activation='relu' ))2 , 2 )))32 , (3 , 3 ), activation='relu' ))2 , 2 )))64 , (3 , 3 ), activation='relu' ))2 , 2 )))64 , activation='relu' ))0.5 ))6 , activation='softmax' ))compile (loss='categorical_crossentropy' ,'rmsprop' ,'acc' ])
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 from tensorflow.keras.preprocessing.image import ImageDataGeneratorfrom tensorflow.keras.layers import Flatten, Dense, Dropoutfrom tensorflow.keras.models import Sequentialimport efficientnet.tfkeras as efn'imagenet' ,224 , 224 , 3 ),False ,'avg' )0.2 ))1024 , activation='relu' ))0.2 ))512 , activation='relu' ))0.5 ))6 , activation='sigmoid' ))False compile (loss='categorical_crossentropy' ,'adam' ,'acc' ])
以上三个模型中,第三个模型的效果最优 一,二模型是在keras上进行的,而第三个模型是在tensorflow.keras下进行的。
原因是第三个模型采用了EfficientNet是谷歌2019最新的net: EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks ICML 2019。正好我当前采用的tensorflow版本为2.0, tensorflow2.x版本自带了keras,相比较单独使用keras,用tensorflow.keras似乎是种更好的选择,但在EfficientNetB0的问题上,采用efficientnet.tfkeras得到的效果要远比efficientnet.keras好,具体原因暂未知道,可能是前段代码采用的是keras的,而后段代码是tensorflow.keras所导致的
关于安装:
本次安装在经过很多乱七八糟的问题之后,得到了一个相对来说稳定且妥当的方法
采用的是anaconda和Pycharm结合。
为防止项目进展过程中的各第三方库版本不适配问题,必须先用anaconda创建一个新的虚拟环境 ,然后上网查找源并对anaconda进行换源 ,最终在activate虚拟环境内,进行conda install安装各第三方库 即可,值得高兴的是,使用conda install tensorflow-gpu==2.0时,conda将自动安装与其tensorflow-gpu版本相对应的CUDA和cudnn,节省了很多时间。需要注意 ,Pycharm无法自动与我们创建的虚拟环境对接,需要手动对Pycharm进行虚拟环境对接。
关于预测部分的部分代码:
需要注意,加载训练好的模型可能会出现如下问题:
ValueError: Unknown activation function:swish
原因是由于我们采用的是第三种模型,而第三个模型调用的是
import efficientnet.tfkeras as efn
所以在predict.py下,我们也应该添加上面这段代码,添加之后问题解决
以下是三个模型的预测结果:
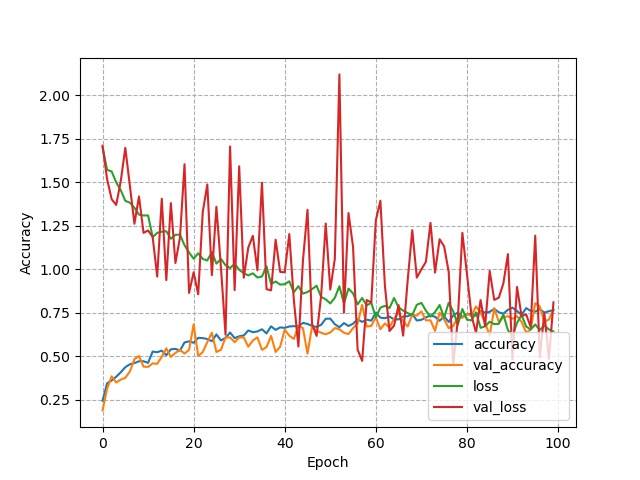
模型1
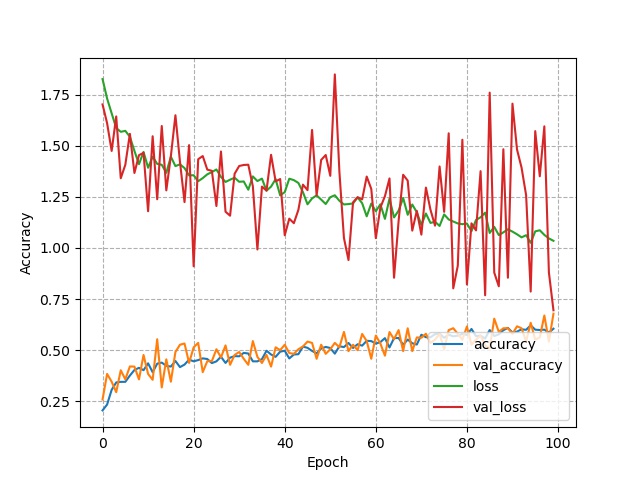
模型2
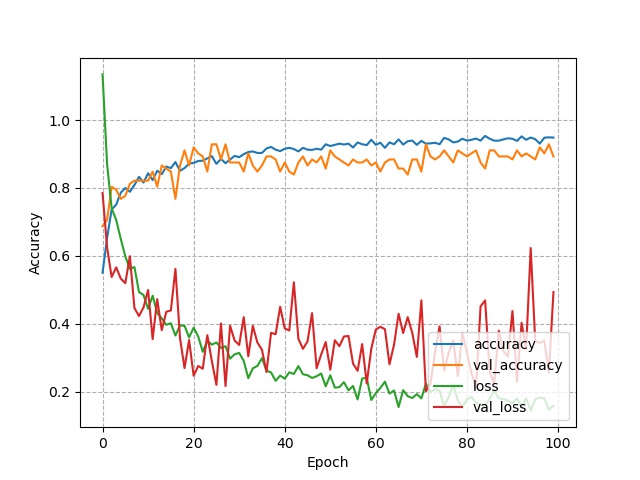
模型3
第三个模型的效果远高于第一二个模型,之后时间允许的话,可以再微调参使其效果更佳。
后续计划:
进行图像定位和语义分割,以及在flask或django框架下部署tensorflow。
django操作日志:
目前暂时采用django2.2结合MySQL8.0.23来部署了tensorflow.keras,已经可以实现由网页端上传图片,后端接收图片,并通过加载训练好的模型来对接收到的图片进行分类,并将分类结果返回给前端。
要注意执行在 终端Terminal 执行 python manage.py runserver 时,首先需要activate ke2 来激活虚拟环境ke2,以确保使用的是我们构建的虚拟环境中的django
点击上方地址即可跳转到创建好的form表单
选择文件并点击提交
点击提交后即可跳转到预测结果的html文件,在前端显示预测结果